In my last post - Time Zone for af:convertDateTime, I introduced how the date values are passed around in an typical ADF application, and specifically, how the ADF Faces handles the date values conversion with respect to the time zone configuration. To review it, let's take a look at this figure again:
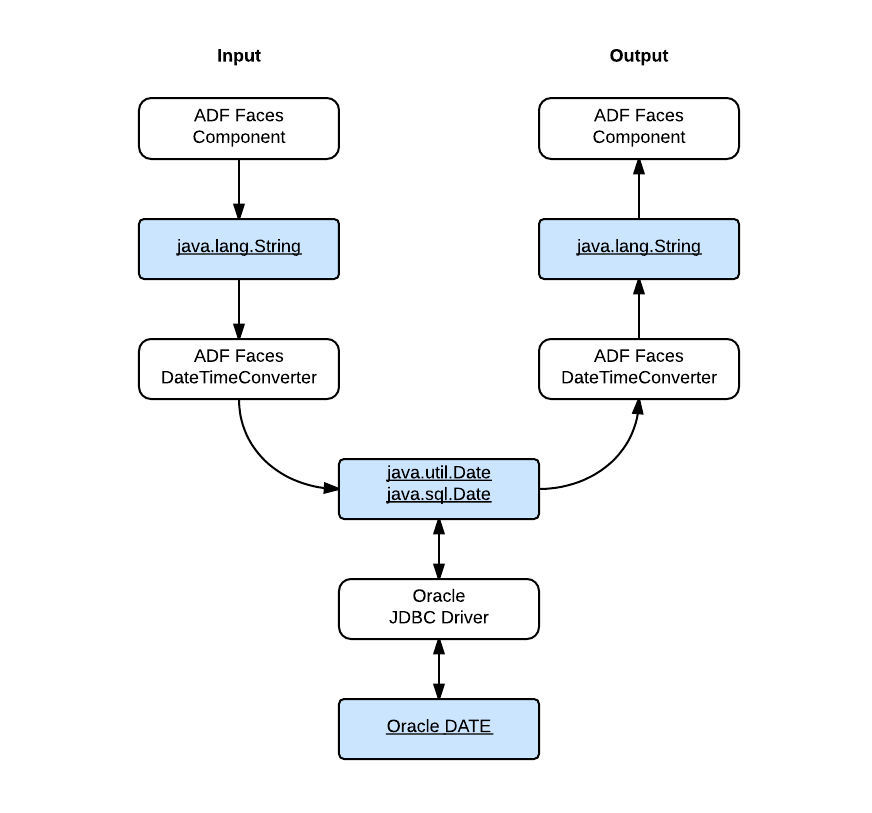
In this post I will be talking about another part of the puzzle - how the Oracle JDBC driver processes date values with regards to time zones. It can be illustrated as the following simple figure:
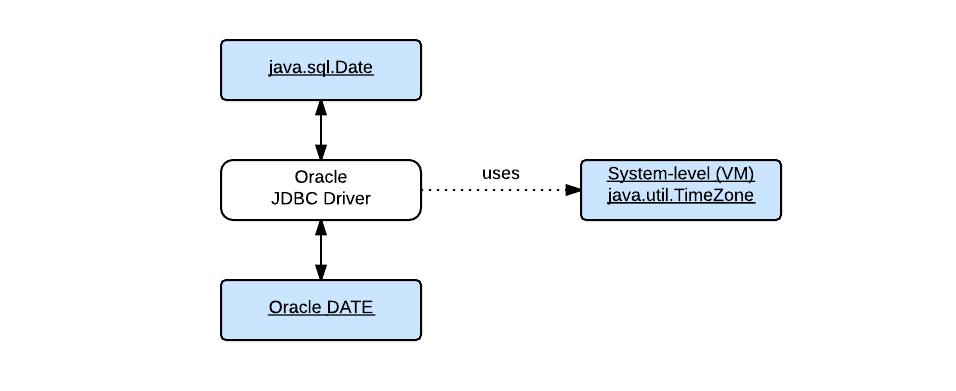
As shown in the figure, this post will use java.sql.Date (or simply Date in monospace type) and the Oracle DATE datatype (or simply DATE in monospace type) for the discussion. The term "date value" will be used for general purposes.
Oracle Database stores date values in its own internal format. A DATE value is stored in a fixed-length field of seven bytes, corresponding to century, year, month, day, hour, minute, and second. When a date value goes from the application to the database; and out of the database back to the application. It works like this, basically:
- A
java.sql.Date value is created to hold the date value, and it's in the time zone GMT.
- The
Date value is sent to the Oracle JDBC Driver, and the driver converts it to the Oracle DATE value and passes it to the database.
- The Oracle JDBC Driver retrieves the
DATE value out of the datbase, converts it back to the java.sql.Date value.
The Java Date value carries the time zone information implicitly which is always GMT by definition; but the Oracle DATE datatype does not. For Oracle JDBC Driver to convert the value between these two datatypes, another time zone must be specified in some way as the source or destination time zone. If you just want a quick answer, here is it: Oracle JDBC Driver will use the default time zone of the Java VM if it's not explicitly specified.
The key lies in the class oracle.sql.Date, which provides conversions between the Oracle DATE datatype and the Java java.sql.Date (and java.sql.Time, java.sql.Timestamp). Specifically, I'll talk about its two overloaded methods used to convert the Oracle DATE value into the Java Date value. The reverse conversions are handled by its constructors with the same ideas shared.
One of methods is:
public static Date toDate(byte[] date, Calendar cal)
And another one is:
public static Date toDate(byte[] date)
Calling the second one is simply equivalent to call toDate(date, null). Let's focus on the first one. This method accepts two parameters. The first parameter represents the Oracle DATE value to be converted with each byte in the array corresponding to each field in the internal format of the Oracle DATE datatype (that seven-byte, fixed-length format). For the other parameter, it's documented as this:
cal - Calendar which encapsulates the timezone information to be used to create Date object
Here is how this method works:
- A new
Calendar instance is created using the TimeZone encapsulated in the specified Calendar parameter (cal1 = Calendar.getInstance(cal.getTimeZone())). In case the Calendar parameter is null, use the default time zone (cal1 = Calendar.getInstance()).
- Populate each field of the new
Calendar instance with the value of each corresponding field in the byte array.
- Create and return a new
java.sql.Date object using the long value of the time returned from the populated Calendar instance (new java.sql.Date(cal1.getTime().getTime())).
In summary, Oracle JDBC Driver interprets the date values retrieved from the database as in the time zone of the Java VM by default. The values that are actually loaded into the Java Date values may vary depending on your Java VM, and vice versa.
Series on Time Zone
Environment
- JDeveloper 12.1.3.0.0 Build JDEVADF12.1.3.0.0GENERIC_140521.1008.S
- Oracle Database 12.1.0
- Oracle JDBC 12.1.0
- Mac OS X Version 10.10
Resources